In the previous blog post, we introduced the background, motivation, objectives, challenges, and goals of this experiment in identifying programming languages in code files.
Introduction
In this post, will go through the benchmarking, testing, and analysis methods that I’m employing in more detail.
Benchmarking procedure
First we’ll go through the benchmarking protocol, called Programming Language Identification (PLI) that we’ve been utilizing on the CodeCommons project [1].
As I’d gone over in the previous post, the project has been heavily making use of the Linguist dataset from GitHub for prototyping and testing prior to full execution on the Software Heritage (SWH) archive [2].
With this dataset, we run the
- selected utility across
- each of the 3039 dataset files
one by one, recording the results.
We receive the results in a parseable .json format.
Accuracy benchmarking
We receive the results of accuracy benchmarking in benchmark-<utility_name>-output.json and they look somewhat like this:
{
"results": [
{
"filename": "/samples/Prolog/dleak-report",
"output": "{\"/samples/Prolog/dleak-report\":{\"lines\":11,\"sloc\":8,\"type\":\"Text\",\"mime_type\":\"text/plain\",\"language\":\"Prolog\",\"large\":false,\"generated\":false,\"vendored\":false}}\n"
},
{
"filename": "/samples/Prolog/plunit_test_example.plt",
"output": "{\"/samples/Prolog/plunit_test_example.plt\":{\"lines\":11,\"sloc\":7,\"type\":\"Text\",\"mime_type\":\"application/vnd.hp-HPGL\",\"language\":\"Prolog\",\"large\":false,\"generated\":false,\"vendored\":false}}\n"
},
{
"filename": "/samples/Prolog/logic-problem.pro",
"output": "{\"/samples/Prolog/logic-problem.pro\":{\"lines\":68,\"sloc\":60,\"type\":\"Text\",\"mime_type\":\"text/plain\",\"language\":\"Prolog\",\"large\":false,\"generated\":false,\"vendored\":false}}\n"
}
]
}
In each entry, we first have the filename, followed by the “output,” including numerous elements of metadata, among which is the identified programming language.
Speed benchmarking
Similarly, we have the speed-related metrics in a benchmark-<utility_name>-hyperfine.json file.
{
"results": [
{
"command": "github-linguist --json '/samples/Prolog/dleak-report' > /results/tmp_file",
"mean": 0.39646997458,
"stddev": null,
"median": 0.39646997458,
"user": 0.36022556,
"system": 0.03594272,
"min": 0.39646997458,
"max": 0.39646997458,
"times": [
0.39646997458
],
"exit_codes": [
0
],
"parameters": {
"filename": "/samples/Prolog/dleak-report"
}
},
{
"command": "github-linguist --json '/samples/Prolog/plunit_test_example.plt' > /results/tmp_file",
"mean": 0.40772620558,
"stddev": null,
"median": 0.40772620558,
"user": 0.36764456,
"system": 0.03987772,
"min": 0.40772620558,
"max": 0.40772620558,
"times": [
0.40772620558
],
"exit_codes": [
0
],
"parameters": {
"filename": "/samples/Prolog/plunit_test_example.plt"
}
},
{
"command": "github-linguist --json '/samples/Prolog/logic-problem.pro' > /results/tmp_file",
"mean": 0.40617827458,
"stddev": null,
"median": 0.40617827458,
"user": 0.38222656,
"system": 0.023823719999999996,
"min": 0.40617827458,
"max": 0.40617827458,
"times": [
0.40617827458
],
"exit_codes": [
0
],
"parameters": {
"filename": "/samples/Prolog/logic-problem.pro"
}
}
]
}
With numerous speed-related metrics, namely the time that it required to analyze the file in question.
Analysis
With these benchmark results of accuracy and speed, we are able to analyze the results. Using Pandas data frames and NumPy, we produce numerous analyses in the realm of accuracy and speed.
Accuracy analyses
Amongst several analyses, we produce the
- Success count per language
- Success rate per language
- List of discrepancy files
- Final accuracy statistics
Finally, we produce graphs, visually representing the general accuracy of the utility.
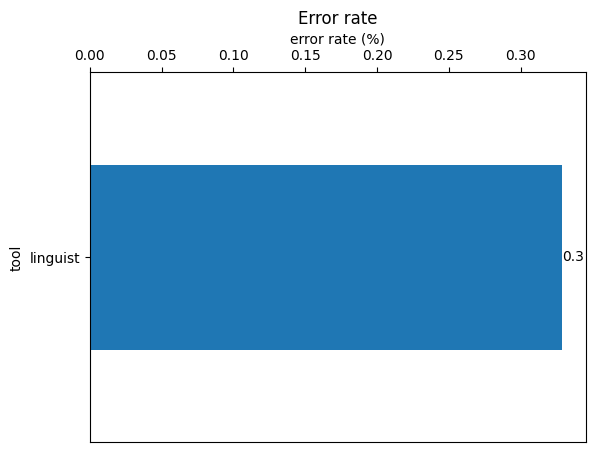
Speed analyses
In this analysis, we produce the
- execution time per file
- execution time per programming language
Likewise, we produce a graph, visually representing general speed of the utility.
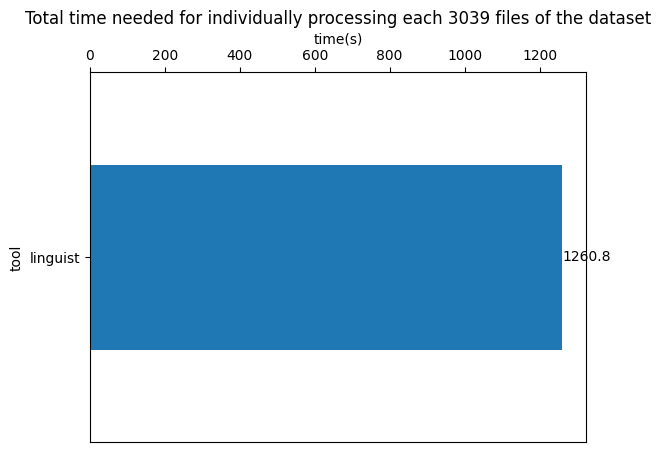
Further references
A full example directory of a full analysis can be found here.
Conclusion
Having discussed the result of the programming language identification benchmarking and the analysis format, we’ll discuss initial results of programming language identification benchmarking in the next post.
References
[1] “PLI Benchmark,” CodeCommons GitLab repository, 20 Nov. 2024. [Online]. Available: https://gitlab.softwareheritage.org/teams/codecommons/pli-benchmark (access restricted).
[2] GitHub, Inc., “Linguist sample files dataset,” GitHub Linguist repository, commit a7e40d3, 2025. [Online]. Available: https://github.com/github-linguist/linguist/tree/main/samples.